探索数据
后面我们将训练 XGBoost 模型来预测广告请求出价的可能性。 这是一个二分类问题,模型根据广告请求的详细信息预测 bid / no_bid。本节我们首先快速探索上一个模块中准备的数据。
打开3_train_xgboost.ipynb, 使用Data Science 3.0内核:

获取sagemaker的execution role:

定义输入和输出路径:

获取train/test/valid数据文件:
def getTrainFiles(file_type='libsvm', bucket_name=INPUT_BUCKET_NAME, prefix=DATA_PREFIX):
items = s3_client.list_objects_v2(Bucket=bucket_name, Prefix=f"{prefix}/train/")
files = []
for itm in items['Contents']:
if itm['Key'].endswith(file_type):
files.append(itm['Key'])
return files
def getValidationFiles(file_type='libsvm', bucket_name=INPUT_BUCKET_NAME, prefix=DATA_PREFIX):
items = s3_client.list_objects_v2(Bucket=bucket_name, Prefix=f"{prefix}/valid/")
files = []
for itm in items['Contents']:
if itm['Key'].endswith(file_type):
files.append(itm['Key'])
return files
def getTestFiles(file_type='libsvm', bucket_name=INPUT_BUCKET_NAME, prefix=DATA_PREFIX):
items = s3_client.list_objects_v2(Bucket=bucket_name, Prefix=f"{prefix}/test/")
files = []
for itm in items['Contents']:
if itm['Key'].endswith(file_type):
files.append(itm['Key'])
return files
file_type = 'parquet'
train_files = getTrainFiles(file_type=file_type)
test_files = getTestFiles(file_type=file_type)
valid_files = getValidationFiles(file_type=file_type)
print(f"Train files: {len(train_files)}")
print(f"Test files: {len(test_files)}")
print(f"Valid files: {len(valid_files)}")
# Train files: 26
# Test files: 26
# Valid files: 26
让我们通过从 S3 下载示例训练/测试/验证文件并将其存储在本地临时文件夹中:
import os
from sklearn.datasets import load_svmlight_file
import pandas as pd
if not os.path.exists(os.path.join("./temp")):
os.makedirs(os.path.join("./temp"))
file_type = 'parquet'
s3_client.download_file(INPUT_BUCKET_NAME, train_files[0], f"./temp/training_set.{file_type}")
s3_client.download_file(INPUT_BUCKET_NAME, valid_files[0], f"temp/validation_set.{file_type}")
s3_client.download_file(INPUT_BUCKET_NAME, test_files[0], f"temp/test_set.{file_type}")
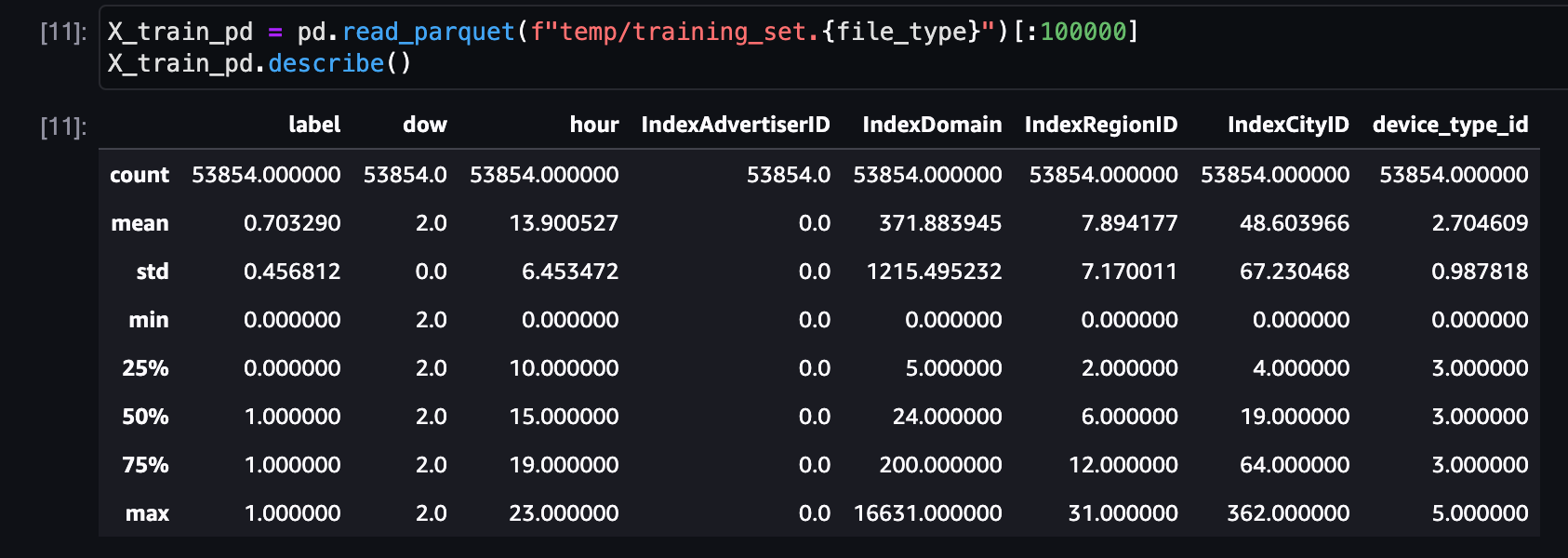
让我们查看前100K行数据,通过查看最小值、最大值、标准差、四分位数和平均值来检查数据摘要:

确认只有numeric数据类型:

检查 bid/no bid的比例
然后,我们检查相关矩阵,并得到一些相关性特征的想法:

我们看到,在这个阶段,device_type_id 与我们的目标标签(bid/no_bid)具有很高的相关性。 此外,特征 dow 和 IndexAdvertiserID 没有值,这是因为样本数据这些列只有一个值。
查看device_type_id和label之间的关系:

我们可以看到label为0时device_type_id的值(左图);当标签为1时(右图),device_type_id有不同的分布:

可视化其他特征相对于标签的分布:
sns.set(font_scale=1.)
for column in X_train_pd.select_dtypes(include=['object']).columns:
if column != 'label':
display(pd.crosstab(index=X_train_pd[column], columns=X_train_pd['label'], normalize='columns'))
for column in X_train_pd.select_dtypes(exclude=['object']).columns:
if column != 'label':
print(column)
hist = X_train_pd[[column, 'label']].hist(by='label', bins=30, sharey=True)
plt.show()
