生成基本配置

本实验由一系列Jupyter Notebook组成,需要共享一些公共数据和配置。作为最佳实践,我们避免在各个笔记本中硬编码这些信息,将这些信息存储在每个笔记本都可以访问的中央位置。
克隆代码库
我们将在Jupyter Notebook上运行数据处理和 ML 模型训练。因此,我们 GitHub 存储库克隆到我们的 SageMaker Studio 中。
打开Studio Classic页面,为当前的用户启动JupyterServer,点击Run:

启动完成后,点击Open:

在窗格中选择git ,然后选择Clone Git Repository:

输入 GitHub 库的 URL :
https://github.com/aws-samples/aws-rtb-intelligence-kit.git

Clone后,Notebook就保存到SageMaker上了,我们将在以下步骤中使用这些Notebook:
0_store_configuration.ipynb1_download_ipinyou_data_tos3.ipynb2_OpenRTB_EMR.ipynb3_train_xgboost.ipynb
这些Notebook存储在aws-rtb-intelligence-kit/source/notebooks。可以通过单击文件夹来查看文件系统:

生成基本配置
我们使用 AWS Systems Manager Parameter Store 作为中心配置存储:
-
Parameter Store是 AWS Systems Manager 的一项功能,为配置数据管理和密码管理提供安全的存储。 -
可以将密码、数据库字符串、Amazon 系统映像 (AMI) ID 和许可证代码等数据存储在里面。可以将值存储为纯文本或加密数据。
打开0_store_configuration.ipynb Notebook,Amazon SageMaker 要求选择notebook environment。为此,需要选择适当的Image和Kernel, 选择Data Science和Python 3:
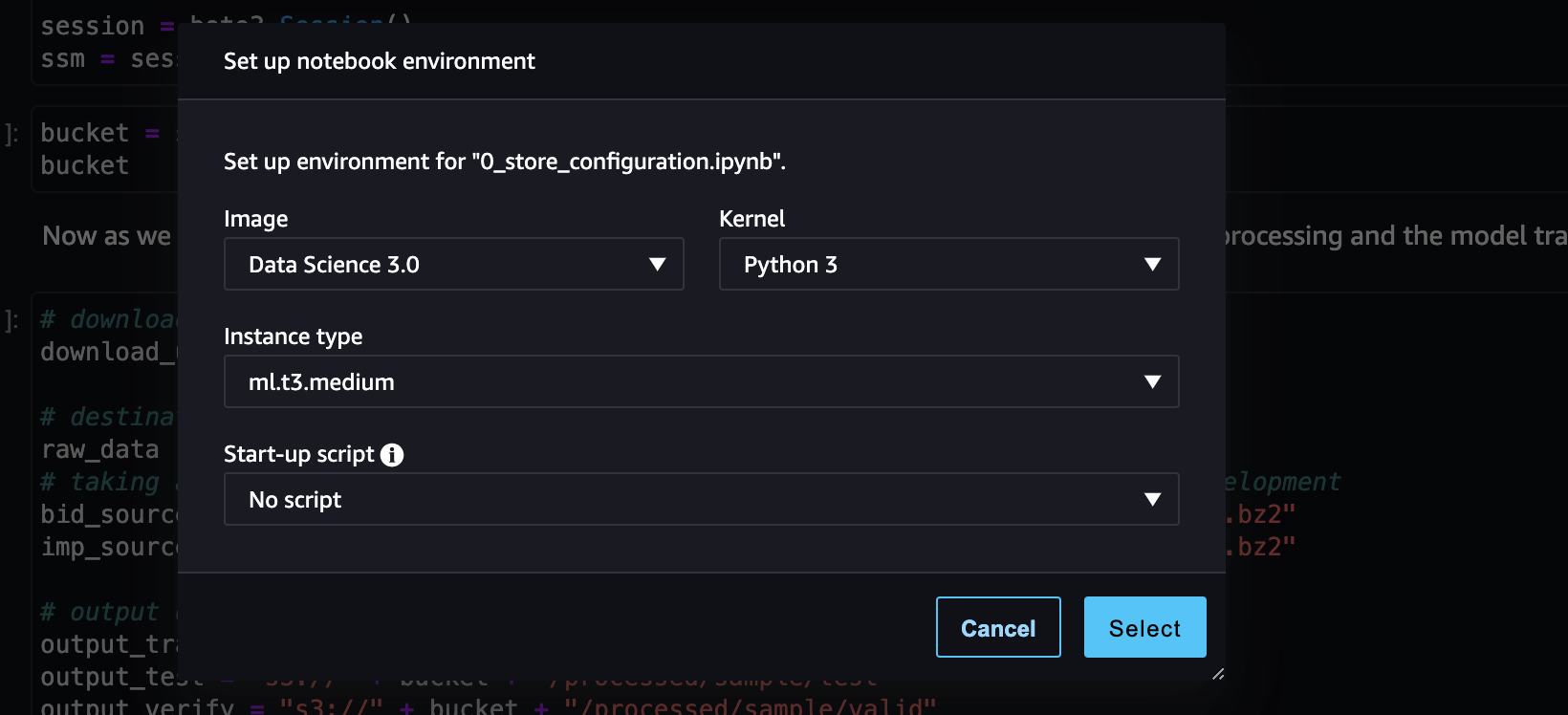
现在我们可以访问Notebook,如下面的屏幕截图所示:

执行笔记本的各个Cell:
import os
import boto3
session = boto3.Session()
ssm = session.client('ssm')
# download url for the example data set
download_url = "https://www.kaggle.com/lastsummer/ipinyou/download"
# destination where we store the raw data
raw_data = "s3://" + bucket + "/raw/ipinyou-data"
# taking a subset of the rawdata to speed up processing and training during development
bid_source = "s3://" + bucket + "/raw/ipinyou-data/training1st/bid.20130311.txt.bz2"
imp_source = "s3://" + bucket + "/raw/ipinyou-data/training1st/imp.20130311.txt.bz2"
# output destinations for the data processing
output_train = "s3://" + bucket + "/processed/sample/train"
output_test = "s3://" + bucket + "/processed/sample/test"
output_verify = "s3://" + bucket + "/processed/sample/valid"
output_transformed= "s3://" + bucket + "/processed/sample/transformed"
pipelineModelArtifactPath = "s3://" + bucket + "/pipeline-model/model.zip"
inference_data = "s3://" + bucket + "/pipeline-model/inference-data/"
inference_schema = "s3://" + bucket + "/pipeline-model/pipeline-schema.json"
binary_model = "s3://" + bucket + "/binary-model/xgboost.bin"
ssm.put_parameter(Name="/aik/download_url", Value=download_url, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/raw_data", Value=raw_data, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/bid_source", Value=bid_source, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/imp_source", Value=imp_source, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/output_train", Value=output_train, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/output_test", Value=output_test, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/output_verify", Value=output_verify, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/output_transformed", Value= output_transformed, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/pipelineModelArtifactPath", Value= pipelineModelArtifactPath, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/inference_data", Value=inference_data, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/xgboost/path", Value=binary_model, Type="String", Overwrite=True)
ssm.put_parameter(Name="/aik/pipelineModelArtifactSchemaPath", Value=inference_schema, Type="String", Overwrite=True)
bucket = ssm.get_parameter(Name="/aik/data-bucket")["Parameter"]["Value"]
download_url = ssm.get_parameter(Name="/aik/download_url")["Parameter"]["Value"]
raw_data = ssm.get_parameter(Name="/aik/raw_data")["Parameter"]["Value"]
bid_source = ssm.get_parameter(Name="/aik/bid_source")["Parameter"]["Value"]
imp_source = ssm.get_parameter(Name="/aik/bid_source")["Parameter"]["Value"]
output_train = ssm.get_parameter(Name="/aik/output_train")["Parameter"]["Value"]
output_test = ssm.get_parameter(Name="/aik/output_test")["Parameter"]["Value"]
output_verify = ssm.get_parameter(Name="/aik/output_verify")["Parameter"]["Value"]
output_transformed = ssm.get_parameter(Name="/aik/output_transformed")["Parameter"]["Value"]
pipelineModelArtifactPath = ssm.get_parameter(Name="/aik/pipelineModelArtifactPath")["Parameter"]["Value"]
inference_data = ssm.get_parameter(Name="/aik/inference_data")["Parameter"]["Value"]
binary_model = ssm.get_parameter(Name="/aik/xgboost/path")["Parameter"]["Value"]
inference_schema= ssm.get_parameter(Name="/aik/pipelineModelArtifactSchemaPath")["Parameter"]["Value"]
print(f'bucket={bucket}')
print(f'download_url={download_url}')
print(f'raw_data={raw_data}')
print(f'bid_source={bid_source}')
print(f'imp_source={imp_source}')
print(f'output_train={output_train}')
print(f'output_verify={output_verify}')
print(f'output_test={output_test}')
print(f'output_transformed={output_transformed}')
print(f'pipelineModelArtifactPath={pipelineModelArtifactPath}')
最后的输出如下,我们在里面定义了各个模块在S3的存储路径:
