使用Autopilot训练模型
Data Wrangler提供了一个统一的体验,使我们能够准备数据并无缝地训练机器学习模型,全部都在该工具内完成。
可以使用SageMaker Autopilot自动训练、调优和部署我们在数据流中转换的数据。Amazon SageMaker Autopilot可以遍历多种算法,并使用最适合数据的算法。
在训练和调优模型时,Data Wrangler会将数据导出到Amazon S3位置,以便SageMaker Autopilot可以访问。
选择流程中最后一个转换节点旁边的+,然后选择create model:
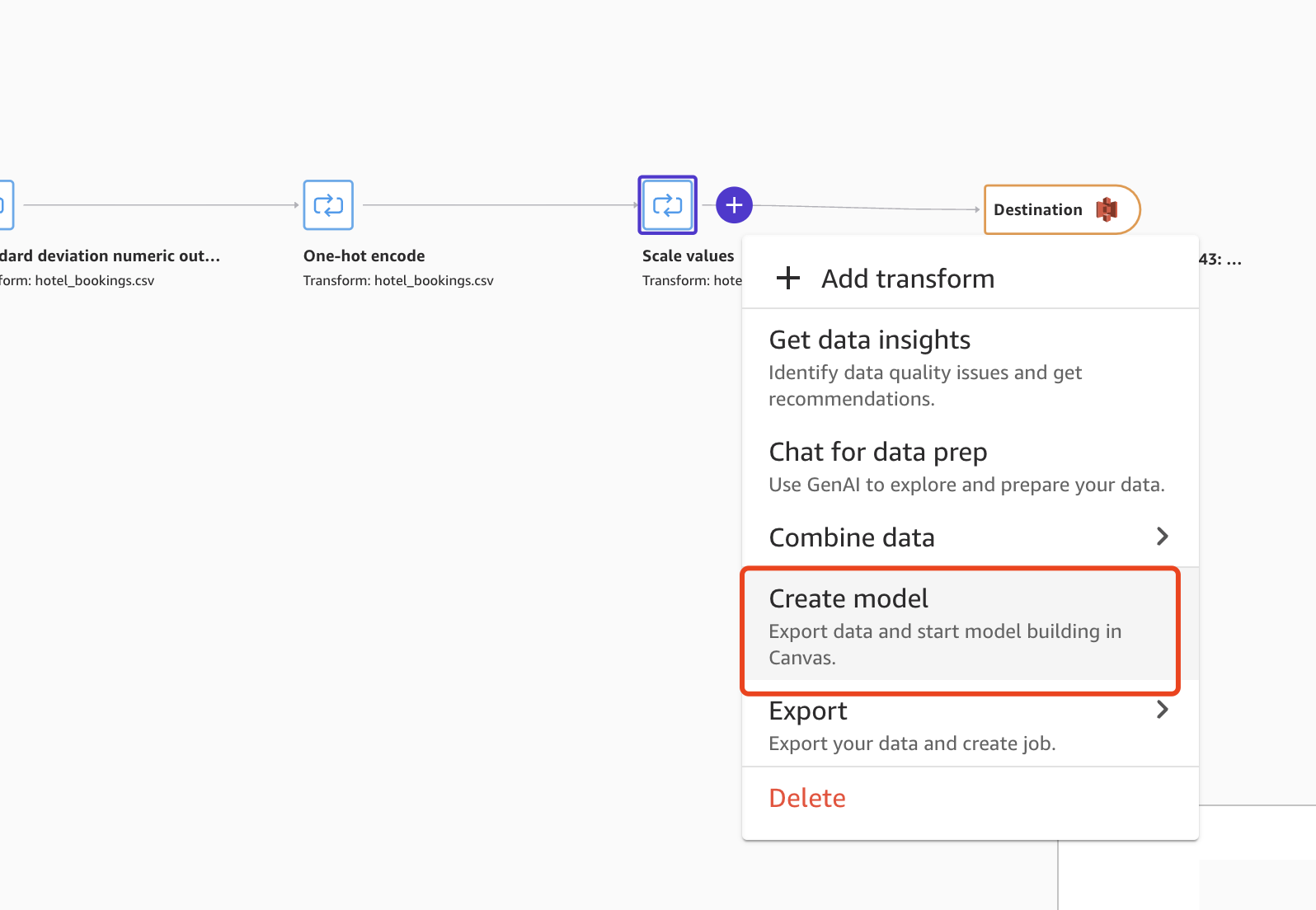
对于Amazon S3位置,请指定SageMaker导出我们数据的Amazon S3位置。 如果默认显示根存储桶路径,Data Wrangler将在其下创建一个唯一的导出子目录 - 除非我们想要修改此默认根路径,否则无需进行任何修改。
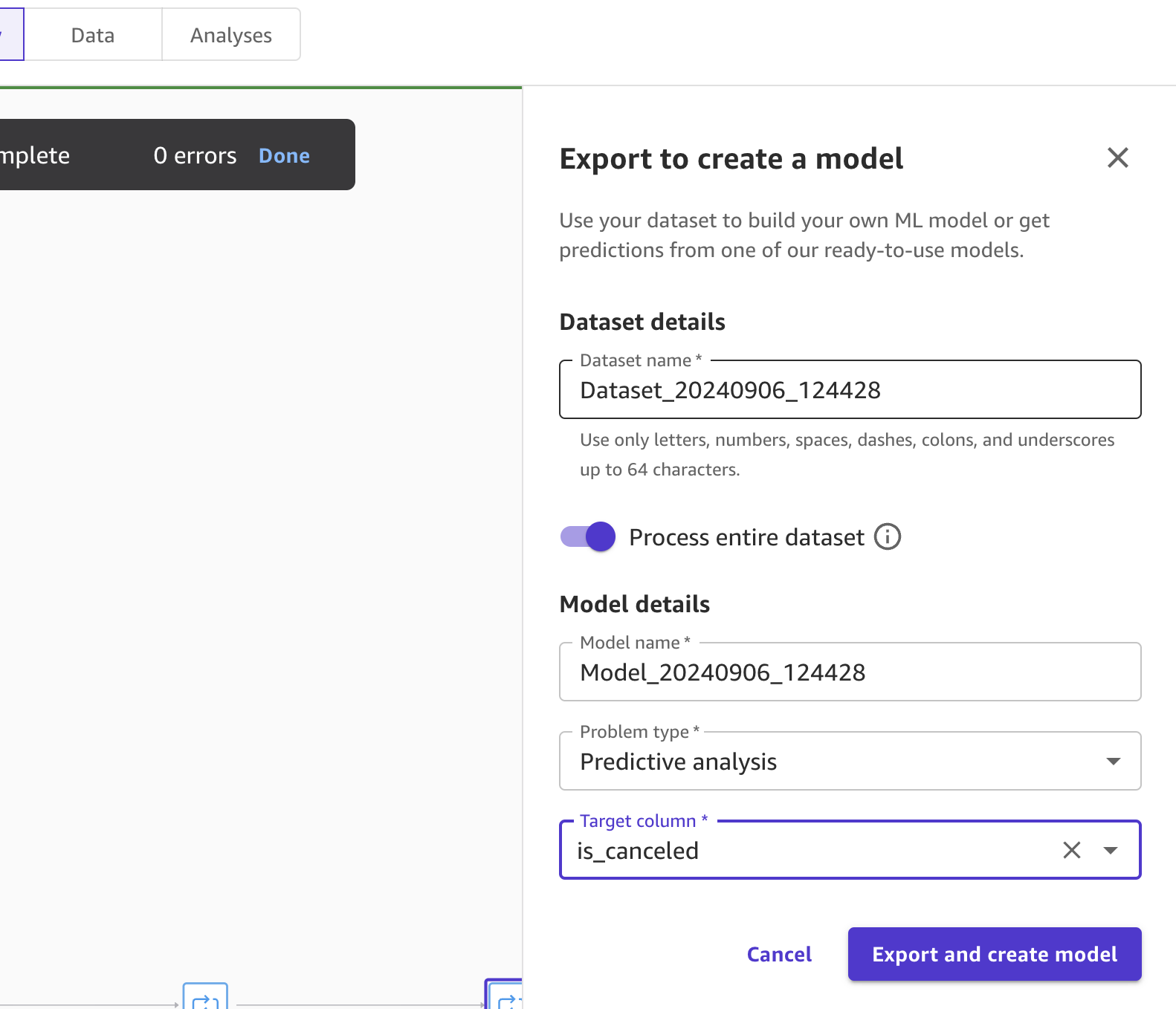
我们可以接受默认设置,然后单击导出并训练按钮将转换后的数据导出到S3。

创建Autopilot实验
导出成功后,我们将进入创建Autopilot实验的页面,输入数据S3位置已为我们填好(因为它是从前一个屏幕的结果中填充的)。
- 可选地设置实验名称(如果我们不想使用默认名称)。

- 单击下一步: 目标和特征。
选择目标和特征
- 对于目标设置为is_canceled。
- 单击下一步: 训练方法
选择训练方法
正如Amazon SageMaker Autopilot使用由AutoGluon驱动的新集成训练模式最多可快8倍 一文中所详述的,我们可以让Autopilot根据数据集大小自动选择训练模式,或手动选择集成或超参数优化(HPO)训练模式。
每个选项的详细信息如下:
- 自动 - Autopilot根据我们的数据集大小自动选择集成或HPO模式。如果我们的数据集大于100 MB,Autopilot会选择HPO;否则它会选择集成。
- 集成 - Autopilot使用AutoGluon集成技术训练多个基础模型,并使用模型堆叠将它们的预测组合成最佳预测模型。
- 超参数优化 - Autopilot使用贝叶斯优化技术调整超参数,在我们的数据集上运行训练作业,以找到最佳模型版本。HPO会选择与我们的数据集最相关的算法,并选择最佳的超参数范围来调整模型。
- 对于我们的研讨会示例,我们将保留默认的自动选择。
- 选择下一步: 部署和高级设置继续。
选择部署和高级设置
了解部署选项的细节很重要;我们的选择将影响之前在Data Wrangler中进行的转换是否包含在推理管道中:
- 自动部署最佳模型,包含Data Wrangler的转换 - 使用此部署选项,当我们在Data Wrangler中准备数据并通过调用Autopilot来训练模型时,训练好的模型将与所有Data Wrangler特征转换一起部署为SageMaker串行推理管道。这使得在推理时能够自动预处理原始数据,并重复使用Data Wrangler的特征转换。请注意,推理端点期望数据的格式与导入到Data Wrangler流程中的格式相同。除非我们已经在工作流程的其他地方建立了推理转换逻辑,否则建议选择此部署选项。
- 自动部署最佳模型,不包含Data Wrangler的转换 - 此选项部署一个不使用Data Wrangler转换的实时端点。在这种情况下,我们需要在推理之前将Data Wrangler流程中定义的转换应用于我们的数据。
- 不自动部署最佳模型 - 当我们不想创建推理端点时,应该使用此选项。如果我们想生成一个最佳模型供以后使用,例如在本地运行批量推理,这很有用。(这是我们在第1部分中选择的部署选项。)请注意,当我们选择此选项时,通过SageMaker SDK创建的最佳候选模型(来自Autopilot)包含Data Wrangler特征转换作为SageMaker串行推理管道。
对于本文,我们使用"自动部署最佳模型,包含Data Wrangler的转换"选项。
- 对于部署选项,选择自动部署最佳模型,包含Data Wrangler的转换。
- 将其他设置保留为默认值。
- 选择下一步: 审查并创建继续。
审查并创建实验
在"审查并创建"页面上,我们可以看到为Autopilot实验选择的设置摘要。
- 选择创建实验开始模型创建过程。
我们将被重定向到Autopilot作业描述页面。随着模型的生成,它们会显示在"模型"选项卡上。要确认该过程已完成,请转到"作业概况"选项卡,并查看"状态"字段是否显示"已完成”。
我们随时可以从Amazon SageMaker Studio返回到此Autopilot作业描述页面:
- 在SageMaker资源下拉菜单中选择"实验和试验”。
- 右键单击我们之前创建的实验,然后选择"描述AutoML作业”。
查看模型训练结果
当Autopilot完成实验时,我们可以从Autopilot作业描述页面查看训练结果并探索最佳模型。
- 右键单击标记为最佳模型的模型,然后选择在模型详细信息中打开。

性能选项卡显示了几个模型测量指标,包括混淆矩阵、精确度/召回率曲线下的面积(AUCPR)和接收者操作特征曲线下的面积(ROC)。这些说明了模型的整体验证性能,但并不能告诉我们模型是否能很好地推广。
我们仍需要在未见过的测试数据上运行评估,以查看模型的预测准确性(对于这个示例,我们预测个人是否会患糖尿病)。
在下一节中,我们将对我们选择自动部署的实时端点执行推理。