Programatic Export
Data Wrangler支持将Data Wrangler flow以编程方式导出到S3、Feature store、SageMaker Pipelines、Inference Pipelines和Python代码。
导出到 SageMaker Pipelines
当我们想要构建和部署大规模机器学习 (ML) 工作流程时,可以使用 SageMaker Pipelines 创建端到端工作流程,管理和部署 SageMaker 作业。
SageMaker Pipelines 使我们能够构建管理 SageMaker 数据准备、模型训练和模型部署作业的工作流程。我们可以使用 SageMaker 提供的第一方算法来使用 SageMaker Pipelines。
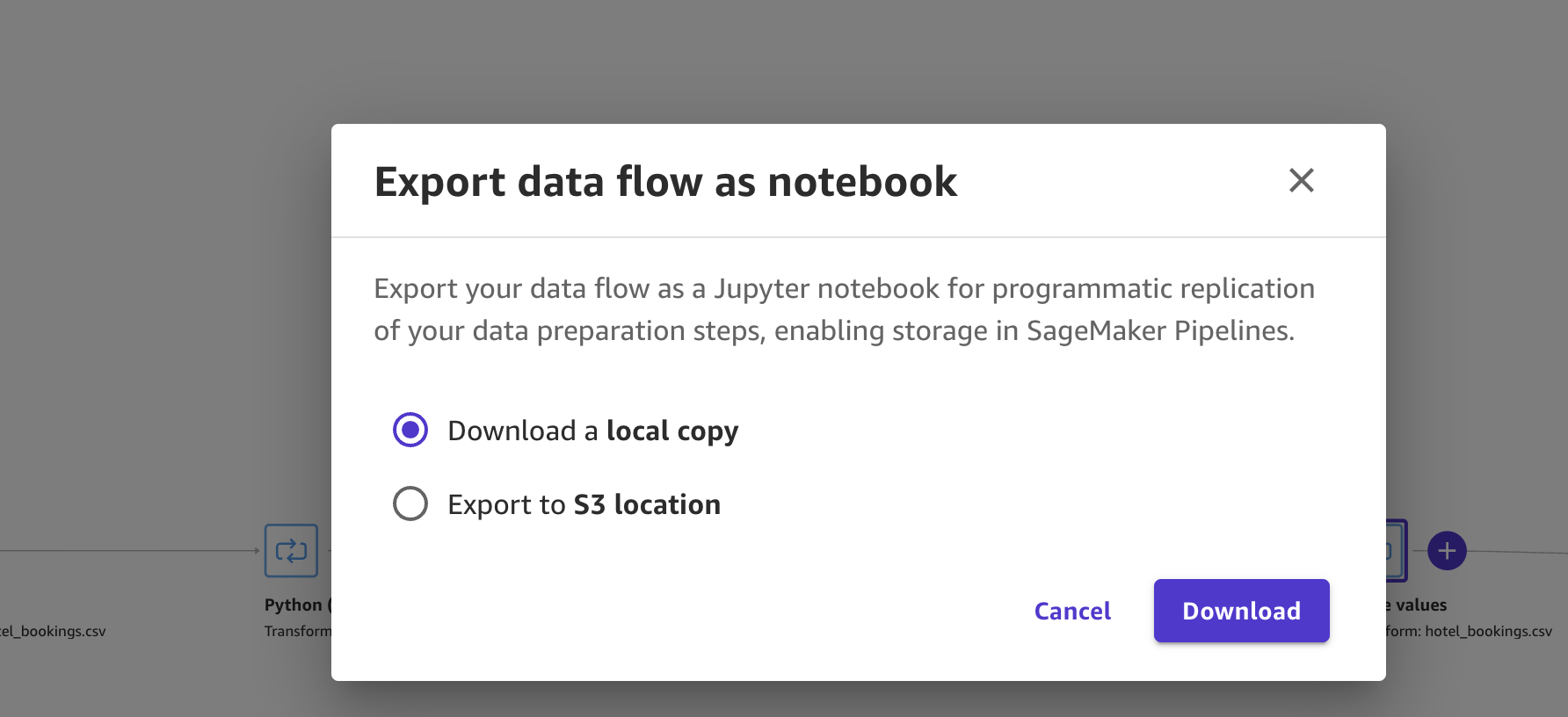
选择+号,export -> export via jupyter notebook:

然后选择SageMaker Pipelines:

选择下载到本地:
下载文件包含管道代码的notebook:

Data Wrangler 生成的 Jupyter Notebook 可用于定义管道。该管道包括由我们的 Data Wrangler 流程定义的数据处理步骤。
我们可以通过将步骤添加到以下代码中的步骤列表来向管道添加其他步骤:
pipeline = Pipeline(
name=pipeline_name,
parameters=[instance_type, instance_count],
steps=[step_process], #将更多步骤添加到此列表以在我们的管道中运行
)
将数据导出到 Amazon S3
跟上面一样,选择导出到jupyter,然后选择S3:

同样生成一个ipynb文件:

在jupyter notebook中执行相应代码,能够执行之前的transform流程,将数据输出到s3